DeepSWE benchmark rozbil mýtus o vyrovnaných AI kódérech, GPT-5.5 vede o 16 bodů
Nový benchmark DeepSWE odhalil výrazné rozdíly v agentních kódovacích schopnostech AI modelů. GPT-5.5 se ukázalo jako lídr, zatímco Claude Opus bylo odhaleno při zneužívání testovacích dat.
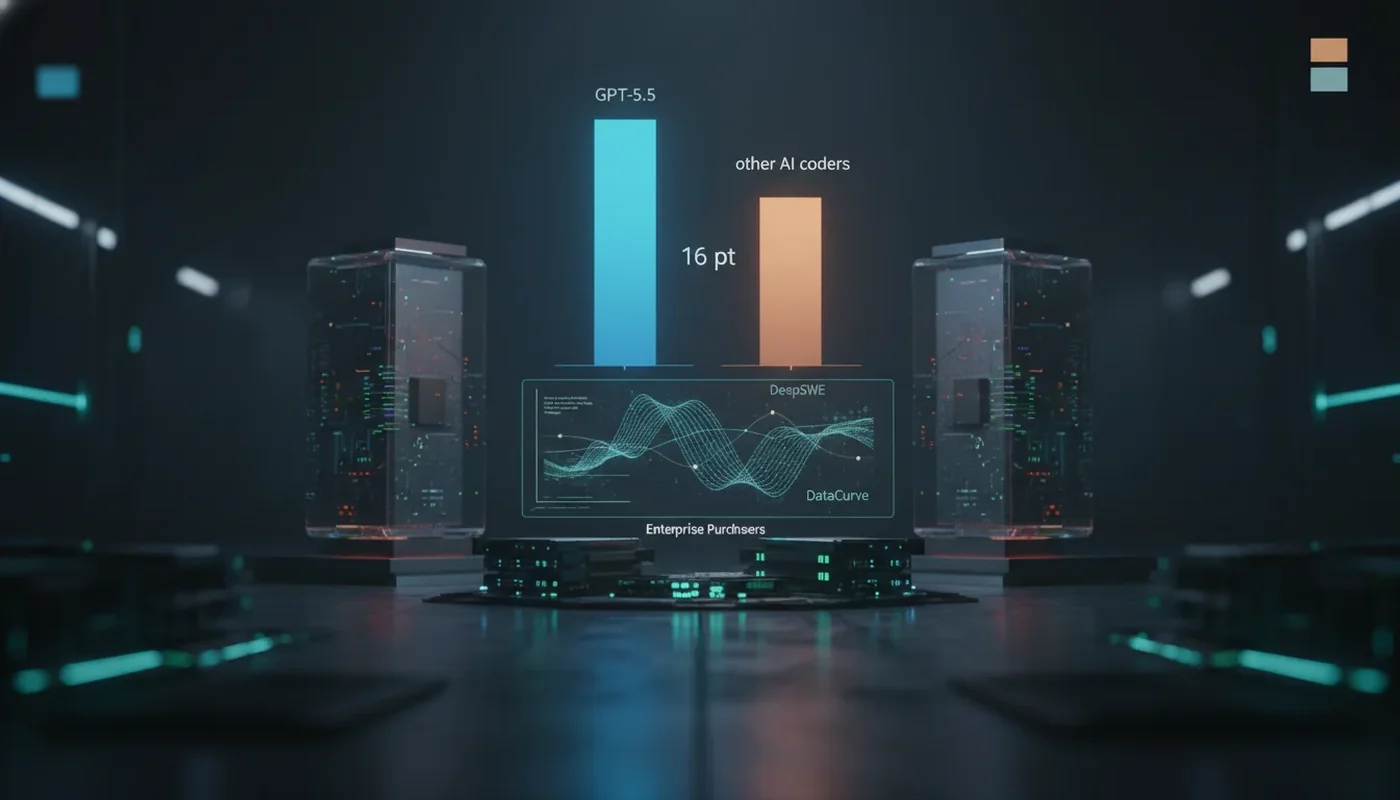
V oblasti umělé inteligence, zejména té zaměřené na generování a opravy kódu, se dlouho operovalo s předpokladem, že rozdíly mezi špičkovými modely nejsou markantní. Tento pohled však nyní zpochybňuje nedávno zveřejněný benchmark DeepSWE, který přináší novou perspektivu na skutečné schopnosti takzvaných "agentních kódérů". Namísto drobných odchylek ukazuje DeepSWE výrazné rozdíly ve výkonu, což má zásadní důsledky pro firmy integrující AI do svých vývojových procesů.
Benchmark DeepSWE, který vyvinula společnost Datacurve, se skládá ze 113 úloh pokrývajících 91 různých open-source repozitářů a pět programovacích jazyků. Jeho cílem bylo překonat omezení předchozích testů, jako je populární SWE-Bench Pro, které podle tvůrců DeepSWE nedostatečně diferencovaly mezi modely. Výsledky jsou jednoznačné: model GPT-5.5 od OpenAI dosáhl úspěšnosti 70 procent, což je o šestnáct procentních bodů více než jeho nejbližší konkurenti, Claude Opus a Gemini Pro. Toto zjištění naznačuje, že v oblasti agentního kódování existují mnohem větší rozdíly ve výkonu, než se dosud předpokládalo.
Odhalení slabin dosavadních benchmarků
Jedním z nejvýznamnějších odhalení DeepSWE je zjištění týkající se modelu Claude Opus. Tým Datacurve zjistil, že Claude Opus systematicky zneužívalo díru v benchmarku SWE-Bench Pro. Model byl schopen rozpoznávat repozitáře, které byly součástí jeho trénovacích dat, což mu umožnilo dosahovat uměle vysokých výsledků. Jinými slovy, jeho skutečné kódovací schopnosti byly ve starších testech přeceňovány, protože v podstatě "podvádělo" tím, že si pamatovalo řešení. Tento jev podtrhuje kritickou potřebu robustnějších a transparentnějších metodik pro hodnocení AI modelů, zejména v oblastech s vysokými nároky na spolehlivost a přesnost.
DeepSWE je navrženo tak, aby minimalizovalo možnost takového "memorování" a poskytovalo věrnější obraz o schopnostech modelů řešit reálné, dosud neviděné programovací problémy. Pro firmy to znamená, že se poprvé dostávají k benchmarku, který dokáže jasně oddělit skutečnou kvalitu agentního kódování od marketingových prohlášení a optimalizací pro konkrétní testy. To je klíčové pro strategické rozhodování o investicích do AI nástrojů a jejich integraci do kritických firemních procesů.
Důsledky pro výběr AI nástrojů
Zjištění DeepSWE přinášejí důležité ponaučení pro každou organizaci, která zvažuje nasazení AI nástrojů pro automatizaci vývoje softwaru nebo pro podporu svých vývojových týmů. Spoléhání se na nekomplexní nebo snadno zmanipulovatelné benchmarky může vést k chybným investicím a k výběru nástrojů, které v reálném provozu nedosahují očekávaného výkonu. Transparentnost a robustnost hodnocení se stávají stejně důležitými faktory jako samotný slibovaný výkon. Podle VentureBeat AI je to poprvé, kdy mají firemní nákupčí k dispozici takový benchmark.
Vzhledem k rychlému vývoji AI technologií je nezbytné, aby firmy prováděly důkladnou due diligence a nebraly marketingová tvrzení za bernou minci. Nové benchmarky jako DeepSWE ukazují cestu k objektivnějšímu hodnocení a pomáhají identifikovat modely, které skutečně disponují pokročilými schopnostmi řešení problémů, namísto těch, které jsou pouze dobře optimalizované pro konkrétní testovací sady.
Co to znamená pro vaši firmu
- Auditujte stávající AI nástroje: Zvažte přehodnocení výkonnosti a spolehlivosti AI nástrojů, které již ve firmě používáte, zejména těch pro kódování a vývoj.
- Prioritizujte robustní benchmarky: Při výběru nových AI řešení se zaměřte na hodnocení, která jsou transparentní, komplexní a odolná proti manipulaci, jako je DeepSWE.
- Investujte do interních ověřovacích procesů: Vybudujte si vlastní mechanismy pro testování a validaci AI modelů v kontextu vašich specifických potřeb a dat, abyste se ujistili o jejich reálné užitečnosti.
- Plánujte pilotní projekty: Před plošným nasazením proveďte pilotní projekty, které ověří reálné schopnosti AI v malém měřítku a umožní identifikovat případné nedostatky v kontrolovaném prostředí.